
Plus vous êtes gros, plus vous pouvez récolter de données. Mais l'accumulation de données crée-t-elle nécessairement des monopoles sur l'IA et les marchés connexes du machine learning?
Par: Julia Anderson Date: 11 février 2020 Sujet: Politique d'innovation et de concurrence
Chaque nouveau lever de soleil augmente la certitude que le soleil se lèvera demain. Plus nous en savons sur le passé, mieux nous pouvons prédire l'avenir. Il en va de même pour d'importantes applications d'IA et d'apprentissage automatique (ML), où de grands volumes de données sont nécessaires pour atteindre des niveaux commercialisables de précision prédictive.
Pour maintenir le dynamisme sur les marchés du BC, les autorités de la concurrence doivent donc veiller à ce que tous les participants accèdent aux données dont ils ont besoin pour rivaliser de manière viable. Mais combien suffit-il? Est-ce toujours mieux, ou y a-t-il un point où des observations supplémentaires ne changent pas grand-chose aux prévisions? Faut-il observer le soleil se lever un milliard de fois pour savoir ce qui se passera demain?
Les données de formation sont une ressource rare
Comme détaillé dans un blog précédent, le machine learning (ML), un sous-domaine de l'IA, est une technologie de prédiction qui génère de nouvelles informations («prédictions») basées sur des informations existantes («données»). Les applications ML notables incluent la conduite automatisée, la reconnaissance d'image, le traitement de la langue et la recherche. (1)
Comme tout produit, les modèles ML sont aussi bons que la matière première. L'accès à des données de formation adéquates est essentiel pour les fournisseurs d'applications ML – qui L'économiste est allé jusqu'à être qualifié de «ressource la plus précieuse au monde» (2).

Où les fournisseurs et les adopteurs de BC obtiennent-ils cette précieuse ressource? Varian (2018) répertorie huit sources potentielles, notamment: en tant que sous-produit des opérations (par exemple, générées à partir de machines et de capteurs), le raclage Web, les fournisseurs de données (par exemple Nielsen), les fournisseurs de cloud (par exemple Amazon), les données du secteur public et l'offre un service (par exemple ReCAPTCHA).
Pourtant, malgré une variété de sources, les données de formation peuvent être un goulot d'étranglement important pour les entreprises qui tentent de développer ou de mettre en œuvre le ML – et une préoccupation permanente pour les modèles de ML qui nécessitent un recyclage régulier. Selon un rapport de la Commission européenne de 2019, l'accès à des données de formation adéquates est un facteur limitant clé pour le développement des applications ML. (3)
Un problème particulier est que les données doivent être « volumineuses '' – un terme qui est souvent utilisé pour désigner des ensembles de données pour lesquels les observations individuelles comportent peu de contenu informatif, de sorte que la valeur est dérivée du fait d'avoir un grand nombre d'observations (Chakraborty, 2017). Dans de nombreuses applications ML, le volume de données affecte considérablement les performances du modèle. Les algorithmes de reconnaissance d'image, par exemple, doivent être formés sur de gros volumes de données (Carrière-Swallow et al., 2019). La question ici est: combien de données (pertinentes) suffisent pour faire un modèle de ML valable? (4)
Économies d'échelle et volume de données nécessaires
La relation entre le volume de données et les retours de ML est un sujet controversé. Hal Varian et Pat Bajari, respectivement économistes en chef chez Google et Amazon, affirment que la précision du modèle augmente avec la taille de l'échantillon de données, mais à un rythme décroissant. (5) Intuitivement, en m'enseignant (ou un algorithme) à quoi ressemble Labradors, le les dix premiers labradors sont plus instructifs que les dix suivants. En termes techniques, les données présentent des «rendements d'échelle décroissants».
La figure 1 illustre comment la valeur des photos de chiens supplémentaires pour améliorer un algorithme de vision industrielle diminue lentement à mesure que la taille de l'échantillon d'apprentissage augmente. (6)
Figure 1. Diminution des rendements d'échelle des données de Stanford Dogs pour la précision du ML
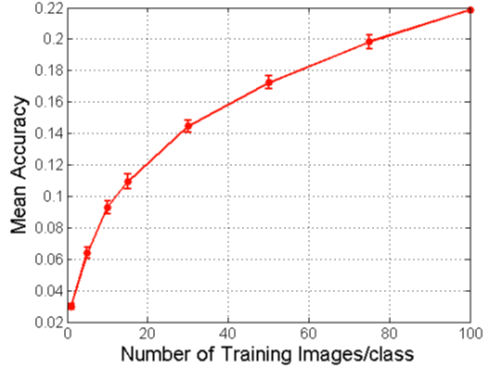
Source: Varian (2018)
Si les données présentent des rendements d'échelle décroissants, nous pourrions en conclure que les entreprises n'ont besoin que de sécuriser une somme forfaitaire suffisamment importante pour être viables. Les économistes Ajay Agrawal, Joshua Gans et Avi Goldfarb sont en désaccord. (7) Leur argument est le suivant: même si les données présentent des rendements décroissants (comme dans la figure 1), une légère avance dans la quantité de données peut induire une légère avance dans la qualité qui attire les utilisateurs . Plus d'utilisateurs génèrent plus de données, ce qui améliore la qualité. Il s'agit de ce que l'on appelle la «boucle de rétroaction des données» illustrée à la figure 2. Au fil du temps, un petit avantage de données initial peut se traduire par une part importante de la base d'utilisateurs et du marché. À long terme, cette dynamique d'auto-renforcement peut conduire à une domination du marché.
Essentiellement, Agrawal et al. faire la distinction entre les rendements techniques des données (c.-à-d. l'exactitude) et les rendements économiques des données (c.-à-d. les parts de marché), et faire valoir que même si les données montrent des rendements décroissants au sens technique (comme dans la figure 1), les rendements peuvent augmenter au sens économique.
Figure 2. La boucle de rétroaction des données
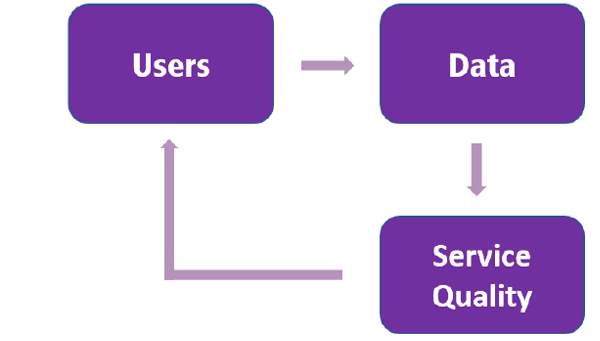
Source: basé sur OCDE (2016)
L'un des mécanismes sous-jacents à la boucle de rétroaction des données est lié à la granularité accrue qui accompagne le volume. Les opinions divergentes de Google et de Microsoft dans le domaine de la recherche Internet ML illustrent ce point. (8)
Microsoft, en justifiant un accord de 10 ans pour la recherche Yahoo en 2009 (9), a avancé que des performances plus élevées sont une conséquence directe de l'échelle. (10) À la suite de cet argument, l'algorithme de recherche Google est meilleur que Yahoo parce que plus de gens utilisent Google. Plus de personnes utilisent Google signifie que Google peut collecter plus de données et fournir de meilleurs résultats de recherche, attirer plus d'utilisateurs, etc. C'est la boucle de rétroaction en action.
Google a exprimé son scepticisme quant à l'argument de l'échelle de Microsoft. (11) Les milliards de recherches de Yahoo devraient être suffisantes pour concurrencer efficacement. (12) Les performances inférieures de Yahoo refléteraient la qualité inférieure de son algorithme (13) plutôt que la quantité de données qu'il contient. Pour citer le Varian de Google: « ce ne sont pas la quantité ou la qualité des ingrédients qui font la différence, ce sont les recettes ».
Microsoft a répliqué que ses milliards de recherches sont insuffisantes. De nombreuses requêtes sont extrêmement rares et, pour ces requêtes, Google a plus de points d'observation, simplement parce qu'il contient plus de données. Google produit ainsi de meilleurs résultats pour les requêtes rares. (14)
Les travaux empiriques de Schaefler et al. (2018) justifient les affirmations de Microsoft. Schaefler et al. (2018) examinent l'impact des données supplémentaires des utilisateurs sur la qualité des résultats de recherche sur Internet. Ils démêlent les effets de plus de données de l'effet de meilleurs algorithmes et constatent que les deux sont importants. Dans leur four, l'analogie de Varian tombe à plat: les ingrédients et la recette sont essentiels à une bonne cuisine.
Le désaccord entre Google et Microsoft expose également les fortes hypothèses comportementales et structurelles qui sous-tendent l'argument de la boucle de rétroaction. Dans le cas de la recherche sur Internet, par exemple, l'argument exige que (i) les consommateurs puissent détecter de petites différences de qualité, (ii) les différences de qualité importent aux utilisateurs (ou au moins quelques-uns), et (iii) les coûts de commutation sont suffisamment bas. Le même raisonnement ne devrait cependant pas être valable sur tous les marchés ML.
Dans les applications de synthèse vocale, par exemple, il n'est pas clair que de petites différences de qualité soient évidentes pour l'utilisateur, ou qu'elles importent suffisamment pour justifier les coûts potentiellement importants du changement de fournisseur (par exemple, apprendre à utiliser une nouvelle application). À l'autre extrême, certains domaines d'application sont très sensibles aux différences de qualité. Ce sont des applications où la précision est une question de vie ou de mort. (15) Qui accepterait un meilleur diagnostic médical? (16) Personne ne veut du Dr Bing lorsque le Dr Google est dans le couloir. Pour ces applications, le retour à la qualité de prédiction peut représenter l'ensemble du marché, c'est-à-dire «le gagnant prend tout».
Une grande partie du travail empirique sur les rendements d'échelle des données se concentre sur une seule application ML: la recherche sur Internet. (17) Des recherches supplémentaires sont nécessaires pour déterminer où se situe l'argument de la boucle de rétroaction, car la réponse est susceptible de varier d'un domaine d'application à l'autre.
Économies de portée et volume de données nécessaires
Les rendements d'échelle décroissants, affirment-ils, ne sont valables que dans des contextes statistiques «standards» pré-ML. Les statistiques standard traitent de problèmes relativement simples (par exemple, estimer une moyenne de population) pour lesquels des estimations approximatives sont suffisantes:
Un entrepreneur qui veut ouvrir une entreprise de gestion de patrimoine dans un quartier veut savoir si le revenu moyen est de 100 000 $ ou 200 000 $ mais n'a pas besoin de savoir qu'il est de 201 000 $ plutôt que de 200 000 $. (18)
ML aborde des problèmes beaucoup plus complexes, selon Posner et Weyl. Ces nouvelles tâches plus dures sont plus précieuses que les précédentes, plus faciles. Ils demandent également davantage de données et des données plus complexes. Pour ces problèmes, plus les données sont nombreuses, mieux elles peuvent répondre à ces tâches plus difficiles. Par conséquent, et toujours en suivant Posner et Weyl, plus les données sont importantes, plus elles sont précieuses.
Pour illustrer le point de vue des auteurs, pensez à former un ML pour reconnaître les chiens sur les images. Ce modèle nécessite une certaine quantité de données pour produire des résultats précis. Mais, comme l'illustre la figure 1, la valeur des données supplémentaires tombe au-delà d'un certain seuil. Cependant, à mesure que le volume de données continue de croître (et la complexité qui l'accompagne), l'algorithme continue d'apprendre. À un moment donné, il peut effectuer une tâche supplémentaire et plus complexe, comme étiqueter des objets dans les photographies. Encore une fois, la valeur des données supplémentaires pour la tâche d'étiquetage des objets s'aplatit au-delà d'un certain seuil. Encore une fois, alors que le volume de données continue de croître, l'algorithme continue d'apprendre. À un certain point, il peut effectuer une tâche supplémentaire, encore plus difficile, telle que la compréhension de la nature des actions sur les photographies.
Par conséquent, la valeur des données augmente au point que les problèmes plus difficiles nécessitent plus de données. L'argument de Weyl et Posner est, implicitement, que les données présentent des économies de gamme. Comme l'illustre la figure 3, nous nous retrouvons avec une image qui remet en question l'hypothèse de rendements d'échelle décroissants de Varian. Weyl et Posner notent que la valeur des données peut ne pas augmenter indéfiniment: nous pourrions voir un avenir où ML a «tout appris». Mais jusque-là, affirment-ils, les retours sur le volume de données augmentent.
Figure 3. Valeur des données en fonction du nombre d'observations dans un ML typique
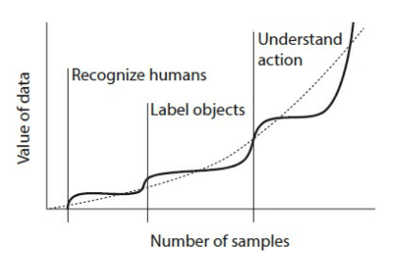
Source: Weyl et Posner (2018)
Les données comme barrière à l'entrée
La théorie économique nous enseigne que, là où les rendements d'échelle augmentent, les monopoles émergent naturellement – la plus grande entreprise étant la plus efficace sur le plan économique. (19) De même, lorsqu'ils se matérialisent, on peut s'attendre à ce que les rendements d'échelle croissants des données contribuent à concentrer l'économie. gains entre les mains des entreprises riches en données.
Cependant, la monopolisation n'est pas nécessairement synonyme de comportement monopolistique, c'est-à-dire. des prix supra-compétitifs, une qualité réduite et / ou une entrave à l'innovation. Tant que les leaders du marché sont confrontés à la perspective d'une entrée concurrentielle par d'autres entreprises, les marchés monopolisés peuvent être compétitifs.
Toutefois, l’augmentation des rendements d’échelle et de la portée des données pourrait, dans certains cas, contribuer à consolider la position du titulaire en créant des barrières à l’entrée très élevées pour les candidats potentiels. Cela pourrait être un problème sur les marchés où il n'y a pas de substitut à un ensemble de données qui est essentiel, c'est-à-dire où il n'y a qu'un seul ensemble de données et qu'il ne peut pas être reproduit, distribué ou acheté. (20) Comme l'a noté le commissaire américain de la FTC, Terrell McSweeny, «il il se peut qu'un titulaire ait des avantages importants par rapport aux nouveaux entrants lorsqu'une entreprise possède une base de données qui serait difficile, coûteuse ou longue à associer ou à reproduire pour une nouvelle entreprise. »(21)
L'avantage historique pourrait être particulièrement prononcé dans l'espace numérique. Les principaux utilisateurs de ML étaient autrefois les principaux collecteurs de données, mais sont de plus en plus des fournisseurs de ML de premier plan. Amazon, par exemple, vendait à l'origine des livres comme moyen de collecter des données personnelles sur des acheteurs riches et éduqués (Ezrachi et al. 2016). Il est désormais l'un des principaux fournisseurs de services ML sur le cloud.
La «rareté des données» semble oxymoronique. Le monde regorge d'informations, jusqu'aux sièges des toilettes, le nouveau foyer de données. Le volume de données créées et copiées chaque année devrait atteindre 44 x 1021 octets en 2020 – 40 fois plus d'octets qu'il n'y a d'étoiles dans l'univers observable. (22) Pourtant, les vastes quantités de données collectées en ligne forment des ensembles uniques de données comportementales qui peuvent être de plus en plus difficiles à reproduire à la lumière de la dynamique d'auto-renforcement décrit ci-dessus.
Pourquoi ne pas laisser les candidats potentiels acheter les données nécessaires dans l'un des nombreux marchés dédiés (tels que datapace.io)? Une préoccupation est que les titulaires de données ont de bonnes raisons de ne pas vendre leurs données: l'augmentation du rendement économique des données a tendance à inciter les entreprises à créer un avantage en matière de données et à ériger des barrières à l'entrée par la suite (Cockburn et al., 2018). Les opérateurs historiques pourraient préférer thésauriser les données qu'ils collectent afin, tout d'abord, de gagner un avantage sur leurs concurrents et, plus tard, de restreindre l'entrée sur le marché (Jones et al., 2018).
Deux facteurs qui pourraient tendre à aggraver ces défis.
Premièrement, comme indiqué précédemment, les entreprises riches en données pourraient bénéficier non seulement d'économies d'échelle, mais aussi d'économies de gamme. Les données acquises dans un but particulier peuvent être précieuses dans d'autres contextes, accordant aux entreprises en place un avantage sur les nouveaux entrants sur les marchés adjacents (Goldfarb et al., 2018). Par exemple, les données collectées dans le cadre de requêtes de recherche peuvent être utilisées pour informer un algorithme de recommandation d'achat. Les économies de gamme pourraient laisser peu de place aux nouveaux entrants potentiels qui souhaitent se développer en dehors des segments de marché des opérateurs historiques.
Deuxièmement, même si une entreprise réussit à pénétrer un nouveau marché d'applications ML, les opérateurs historiques peuvent être en mesure d'utiliser leurs riches données pour détecter la menace concurrentielle et d'acquérir la nouvelle entreprise entrante avant que la position de l'opérateur historique soit contestée (ce qu'on appelle des « acquisitions tueuses '' ').
Implications pour la politique de concurrence(23)
En l'absence d'intervention, un résultat possible sur le marché pourrait être une concentration élevée et une faible contestabilité sur les marchés dépendants des données. Cela implique la nécessité d'un examen minutieux de la politique de la concurrence concernant l'accès aux données. Les ensembles de données uniques et non substituables doivent-ils être considérés comme une «installation essentielle», au même titre que les boucles locales pour la téléphonie fixe? Le partage forcé peut créer des inefficacités, par exemple sous la forme de désincitations à l'investissement, mais la politique de l'UE est bien établie dans de nombreuses industries de réseau. Dans quelles conditions les avantages du partage forcé l'emporteraient-ils sur les coûts?
L'émergence du BC en tant que technologie polyvalente soulève des questions empiriques et normatives difficiles. La relation entre l'accumulation de données et les rendements économiques confère-t-elle aux titulaires riches en données un avantage significatif et auto-renforçant? Les autorités de la concurrence sont-elles équipées pour discerner et analyser les retours monopolistiques basés sur les données? Ces questions figurent en bonne place à l’ordre du jour de la nouvelle Commission européenne (24) et pour de bonnes raisons. Le comportement monopolistique des fournisseurs de BC pourrait ralentir l'adoption de technologies essentielles pour la compétitivité de l'UE, en particulier pour les petites entreprises qui ne disposent pas des connaissances et des ressources nécessaires pour développer des capacités alternatives en interne. Si les révolutions technologiques sont des tremblements de terre de répartition, les autorités de la concurrence devraient veiller à ce que tout le monde se pose sur ses pieds.
Citation recommandée
Lehmann, A. (2020), «Les risques climatiques pour les banques européennes: une nouvelle ère de tests de résistance», Blog Bruegel, 11 février. https://bruegel.org/2020/02/the-dynamics-of-data-accumulation/
(1) Ce post se concentre sur les applications ML.
(2) Voir https://medium.economist.com/will-big-data-create-a-new-untouchable-business-elite-8dc23bcaa7cb
(3) DG COMP 2019, citant https://medium.com/machine-intelligence-report/data-not-algorithms-is-key-to-machine-learning-success-69c6c4b79f33, https: //www.edge. org / response-detail / 26587 et http://www.spacemachine.net/views/2016/3/datasets-over-algorithms.
(4) Bien que cet article se concentre sur les questions relatives au volume de données, d'autres caractéristiques des données sont tout aussi importantes pour générer de la valeur. Il s'agit des autres données dites «4V»: le volume, mais aussi la vitesse (c'est-à-dire la fréquence), la variété (par exemple les données administratives, les données des médias sociaux, les images, etc.) et la véracité (c'est-à-dire représentative de la population cible, sans biais, etc.). Pour une entreprise, avoir un avantage concurrentiel sur ces autres caractéristiques peut également générer d'importants avantages économiques. Aux fins de ce blog, je note que la sécurisation d'un volume suffisant de données semble être nécessaire mais pas suffisante pour avoir une entreprise AI / ML compétitive.
(5) Varian (2018) et Bajari et al. (2018)
(6) En particulier, Bajari et al. (2018) constatent que la longueur des historiques est très utile pour améliorer la qualité des prévisions de la demande, mais à un rythme décroissant; alors que le nombre de produits dans la même catégorie ne l'est pas (à quelques exceptions près où il présente des rendements d'échelle décroissants).
(7) Agrawal, Ajay, Joshua Gans et Avi Goldfarb. 2018a. Machines de prédiction: l'économie simple de l'intelligence artificielle. Cambridge, MA: Harvard Business Review Press.
(8) Comme indiqué dans Goldfarb et al. (2018)
(9) Voir le communiqué de presse de l'accord: https://news.microsoft.com/2009/07/29/microsoft-yahoo-change-search-landscape/
(10) Voir https://www.cnet.com/news/googles-varian-search-scale-is-bogus/
(11) Voir Hal Varian dans une interview CNET: «les arguments d'échelle sont assez faux à notre avis» (https://www.cnet.com/news/googles-varian-search-scale-is-bogus/)
(12) «la quantité de trafic que Yahoo, par exemple, a maintenant concerne ce que Google avait il y a deux ans» et «lorsque nous apportons des améliorations à Google, tout ce que nous faisons est essentiellement testé sur une expérience de 1% ou 0,5% pour voir si c'est vraiment une amélioration. Donc, si vous avez la moitié de la taille, eh bien, vous exécutez une expérience de 2%. « Source: ibid
(13) c'est-à-dire dans l'exécution de tâches telles que l'exploration, l'indexation ou le classement.
(14) La DG COMP de la Commission européenne a formulé des allégations similaires dans le cadre de l'affaire Google Shopping. La DG COMP a affirmé que le service de recherche générale doit recevoir au moins un certain volume minimal de requêtes afin d'améliorer la pertinence de ses résultats pour les requêtes rares, car les utilisateurs évaluent la pertinence d'un service de recherche générale sur la base de requêtes communes et rares. Voir par. 288 de la décision des CE (https://ec.europa.eu/competition/antitrust/cases/dec_docs/39740/39740_14996_3.pdf)
(15) Cockburn et al. (2019).
(16) Un épisode de podcast de The Economist donne vie à ce point (https://www.economist.com/podcasts/2019/10/09/the-promise-and-peril-of-ai)
(17) Voir Schaefler et al. (2018): «Sur aucun autre marché peut-être, la question du rôle des données n'a suscité une discussion aussi vive entre les participants de l'industrie, les experts universitaires et les défenseurs des politiques que dans la recherche générale sur Internet.»
(18) Glen Weyl et Eric Posner, 2018. Marchés radicaux
(19) https://cs.stanford.edu/people/eroberts/cs181/projects/1997-98/microsoft-vs-doj/economics/returns.html
(20) Voir Calvano et al. (2020) pour une étude de la littérature autour de ces questions sur les marchés numériques.
(21) Commissaire Terrell McSweeny, Remarques d'ouverture pour une table ronde, «Pourquoi réglementer les plateformes en ligne?: Transparence, équité, concurrence ou innovation?» Lors de la conférence de l'ARC à Bruxelles, en Belgique, le 5 (9 décembre 2015), https://www.ftc.gov/system/files/documents/public_statements/903953/mcsweeny_-_cra_conference_remarks_9-12-15.pdf.
(22) comprend les données générées en ligne et par l'IoT et les appareils connectés. Source: Word Economic Forum citant Raconteur (https://www.weforum.org/agenda/2019/04/how-much-data-is-generated-each-day-cf4bddf29f/)
(23) Il convient de noter qu'une série de problèmes se situent à l'intersection de la vie privée et de la concurrence, notamment la propriété, la réutilisation, la transparence et le partage des données. Ces problèmes dépassent le score de ce post et ne seront pas explorés ici.
(24) Voir l'énoncé de mission de la présidente de la Commission européenne, Ursula von der Leyen, qui charge Margarethe Vestager: «Au cours des 100 premiers jours de notre mandat, vous coordonnerez les travaux sur une approche européenne de l'intelligence artificielle, y compris ses implications humaines et éthiques . Cela devrait également examiner comment nous pouvons utiliser et partager les mégadonnées non personnalisées pour développer de nouvelles technologies et de nouveaux modèles commerciaux qui créent de la richesse pour nos sociétés et nos entreprises. »(Https://ec.europa.eu/commission/sites/beta -politique / dossiers / mission-lettre-margrethe-vestager_2019_en.pdf)
Bibliographie
Agrawal, Ajay, Joshua Gans et Avi Goldfarb. « Politique économique pour l'intelligence artificielle. » Politique d'innovation et économie 19.1 (2019): 139-159.
Bajari, Patrick et al. « L'impact des mégadonnées sur les performances des entreprises: une enquête empirique. » Documents et actes de l'AEA. Vol. 109. 2019.
Carrière-Hirondelle, M. Yan et M. Vikram Haksar. «L'économie et les implications des données: une perspective intégrée.» (2019).
Chakraborty, Chiranjit et Andreas Joseph. «L'apprentissage automatique dans les banques centrales» (2017).
Cockburn, Iain M., Rebecca Henderson et Scott Stern. «L'impact de l'intelligence artificielle sur l'innovation.» Série de documents de travail du Bureau national de recherche économique w24449 (2018).
Ezrachi, Ariel et Maurice E. Stucke. « Concurrence virtuelle. » Journal of European Competition Law & Practice 7,9 (2016): 585-586.
Goldfarb, Avi et Daniel Trefler. « AI et commerce international. » Série de documents de travail du Bureau national de recherche économique w24254 (2018).
Jones, L. D. et al. « L'intelligence artificielle, l'apprentissage automatique et l'évolution des soins de santé: un avenir radieux ou une source de préoccupation? » Recherche osseuse et articulaire 7,3 (2018): 223-225.
OCDE. «Amener la politique de la concurrence à l'ère numérique». (2016): 1775-1810.
Varian, Hal. « Intelligence artificielle, économie et organisation industrielle. » Série de documents de travail du Bureau national de recherche économique w24839 (2018).
Republication et référencement
Bruegel se considère comme un bien public et ne prend aucun point de vue institutionnel. Tout le monde est libre de republier et / ou de citer ce message sans consentement préalable. Veuillez fournir une référence complète, en indiquant clairement Bruegel et l'auteur concerné comme source, et inclure un hyperlien proéminent vers le message d'origine.


